
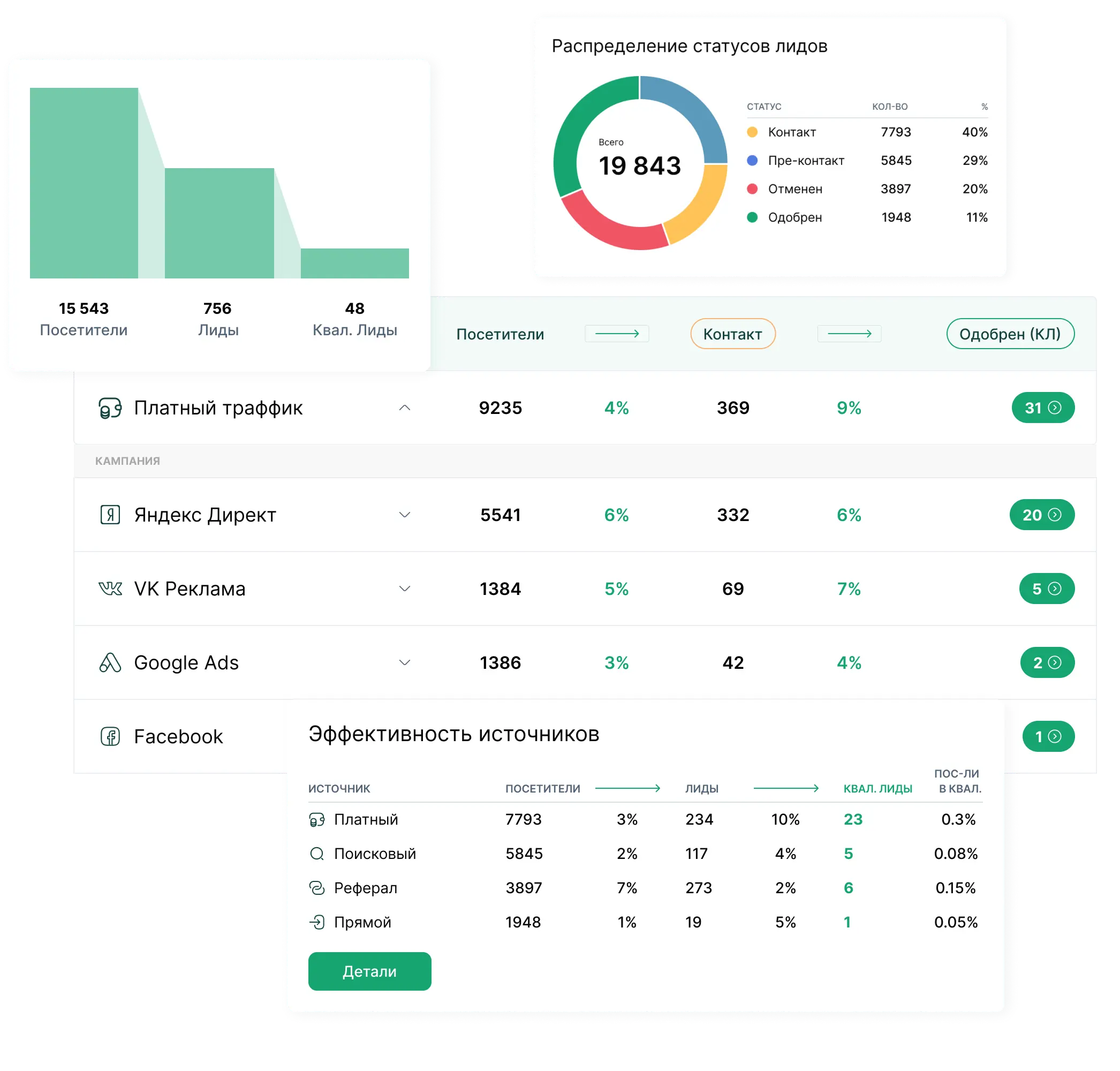
Варианты развертывания ИИ - облако, on-premise, гибрид
Вы решаете, где работает ваш искусственный интеллект. Мы предлагаем три варианта развертывания, которые можно комбинировать. Главное преимущество нашего подхода - RAG база знаний работает с любой LLM моделью. Это значит, что вы можете начать с облака для быстрого старта, а затем перейти на локальные модели для приватности - без переделки базы знаний и интеграций.
- Облако: YandexGPT, DeepSeek - старт за дни
- On-premise: Llama, Mistral, Qwen - данные внутри вашей сети
- RAG база работает с любой моделью - меняйте без переделки
Три подхода к развертыванию
YandexGPT, DeepSeek и другие коммерческие LLM через API. Быстрый старт за дни, без собственной инфраструктуры. Высокое качество ответов, автоматические обновления моделей. Оплата за использование

Llama, Mistral, Qwen, DeepSeek и другие открытые модели на ваших серверах. Полная приватность - данные не покидают ваш контур. Требуются GPU-серверы, но нет зависимости от внешних сервисов

Лучшее из двух миров: облачные модели для общих задач (консультации, FAQ), локальные модели для чувствительных данных (финансы, персональные данные, коммерческая тайна)
Облачные модели - быстрый старт
Облачные LLM модели доступны через API и не требуют собственной инфраструктуры. Вы подключаетесь к провайдеру, и ваш AI-бот или агент начинает работать. Идеально для быстрого старта, пилотных проектов и компаний, которым не критична полная приватность данных.
Без GPU-серверов
- YandexGPT - российский провайдер, данные в РФ
- DeepSeek - высокое качество, конкурентная цена
- Другие коммерческие модели по запросу
- Оплата за токены - платите только за использование
- Автоматические обновления и улучшения моделей
On-premise - полная приватность данных
Открытые модели разворачиваются на ваших серверах или в вашем облаке. Данные никогда не покидают ваш контур - критично для финансовых организаций, медицины, государственных структур и компаний с высокими требованиями к безопасности.
- Llama - одна из лучших открытых моделей от Meta
- Mistral - европейская модель с отличным качеством
- Qwen - мощная модель с поддержкой русского языка
- DeepSeek (open) - открытая версия для локального запуска
- Полный контроль над данными и моделью
- Требуются GPU-серверы (NVIDIA A100/H100 или аналоги)
Гибридный подход - лучшее из двух миров
Не обязательно выбирать одно. Многие компании комбинируют облачные и локальные модели. Например, AI-консультант на сайте работает через облачную модель (быстро, недорого), а обработка финансовых данных и внутренних документов - через локальную модель на вашем сервере. Наша RAG архитектура поддерживает маршрутизацию запросов между моделями.
FAQ, консультации по продуктам, общие вопросы клиентов. Данные не чувствительны, а скорость и качество облачных моделей обеспечивают лучший опыт
Финансовые документы, персональные данные, коммерческая тайна, внутренние регламенты. Обрабатываются только на вашем сервере, без передачи третьим сторонам
Система автоматически определяет тип запроса и направляет его к нужной модели. Правила маршрутизации настраиваются под ваши требования безопасности
Сравнение вариантов
| Параметр | Облако | On-premise | Гибрид |
|---|---|---|---|
| Скорость запуска | Дни | 2-4 недели | 1-3 недели |
| Приватность данных | Данные уходят к провайдеру | Полная - данные в вашем контуре | Настраиваемая по типу данных |
| Инфраструктура | Не нужна | GPU-серверы (NVIDIA) | GPU для приватной части |
| Стоимость | Оплата за токены | Аренда/покупка серверов | Комбинированная |
| Качество моделей | Лучшие коммерческие модели | Хорошее, растет с каждым релизом | Лучшее для каждого типа задач |
| Модели | YandexGPT, DeepSeek | Llama, Mistral, Qwen, DeepSeek | Все доступные |
| Масштабирование | Автоматическое | Ручное (добавление серверов) | Гибкое |
| Кому подходит | Быстрый старт, малый и средний бизнес | Финансы, медицина, госструктуры | Крупный бизнес, холдинги |
RAG база - универсальный фундамент
Ключевое преимущество нашей архитектуры: RAG база знаний не привязана к конкретной LLM модели. Вы можете начать с облачной модели, а позже перейти на on-premise - без переделки базы знаний, без потери данных, без перенастройки интеграций.

Векторная база знаний хранит эмбеддинги - универсальные числовые представления. Они работают с любой LLM: YandexGPT сегодня, Llama завтра, новая модель через год

Переключение между моделями занимает часы, а не недели. Все ваши данные, интеграции и настройки сохраняются. Меняется только «мозг» - LLM модель, которая генерирует ответы
